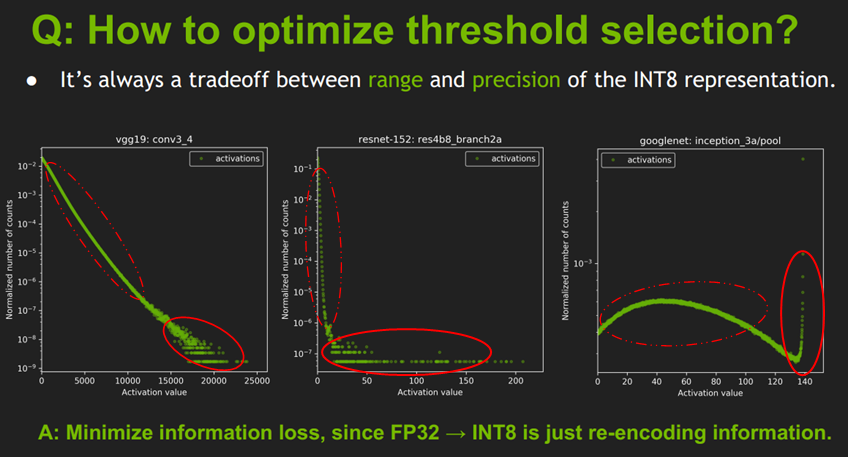
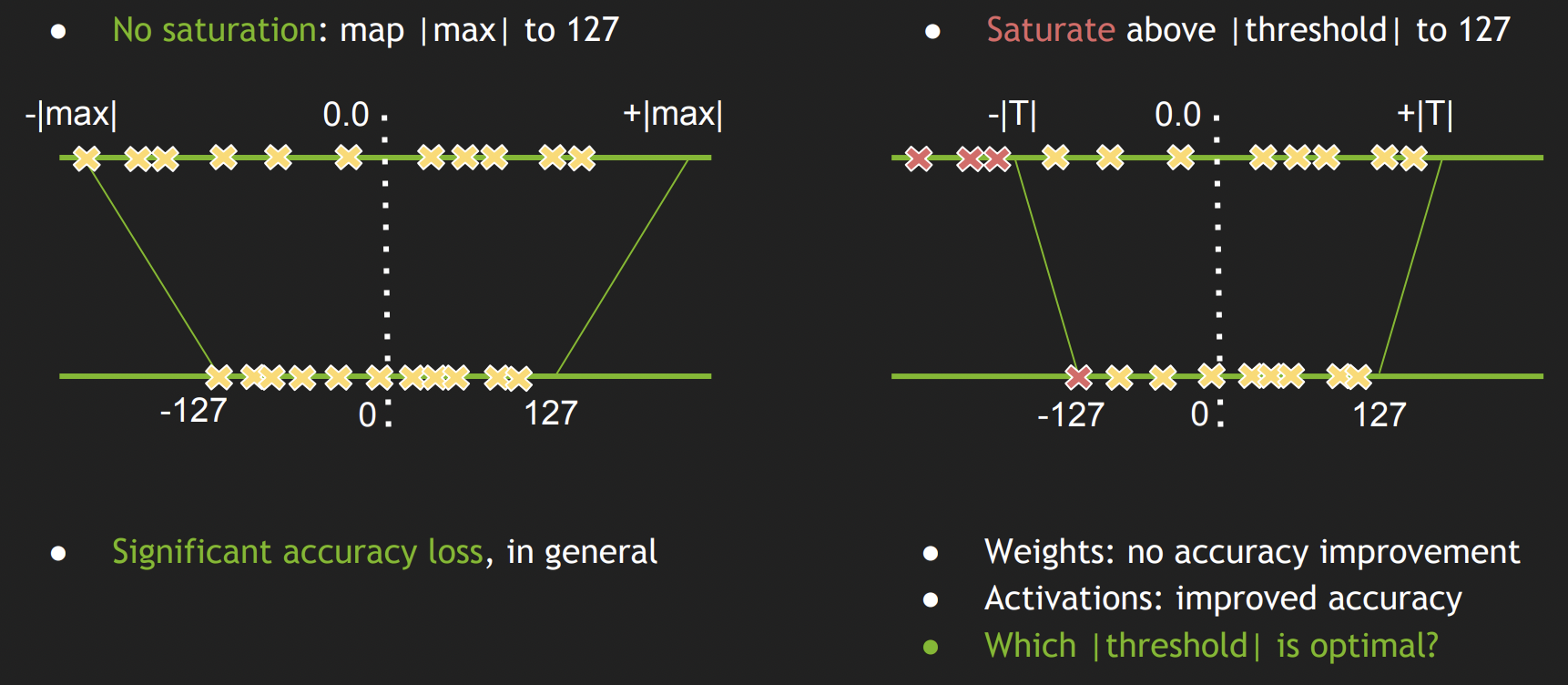
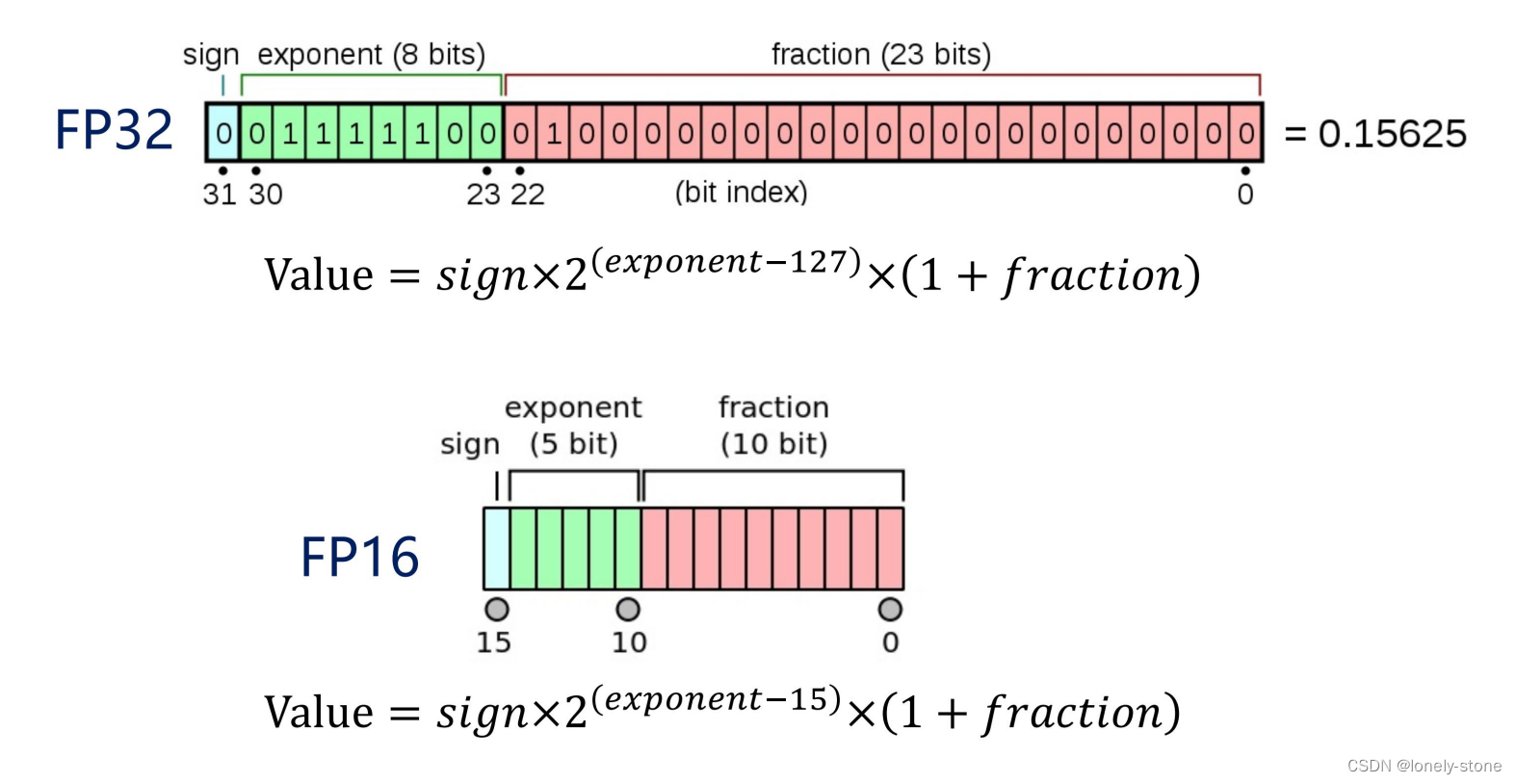
Showing 113 of 113on this page. Filters & sort apply to loaded results; URL updates for sharing.113 of 113 on this page
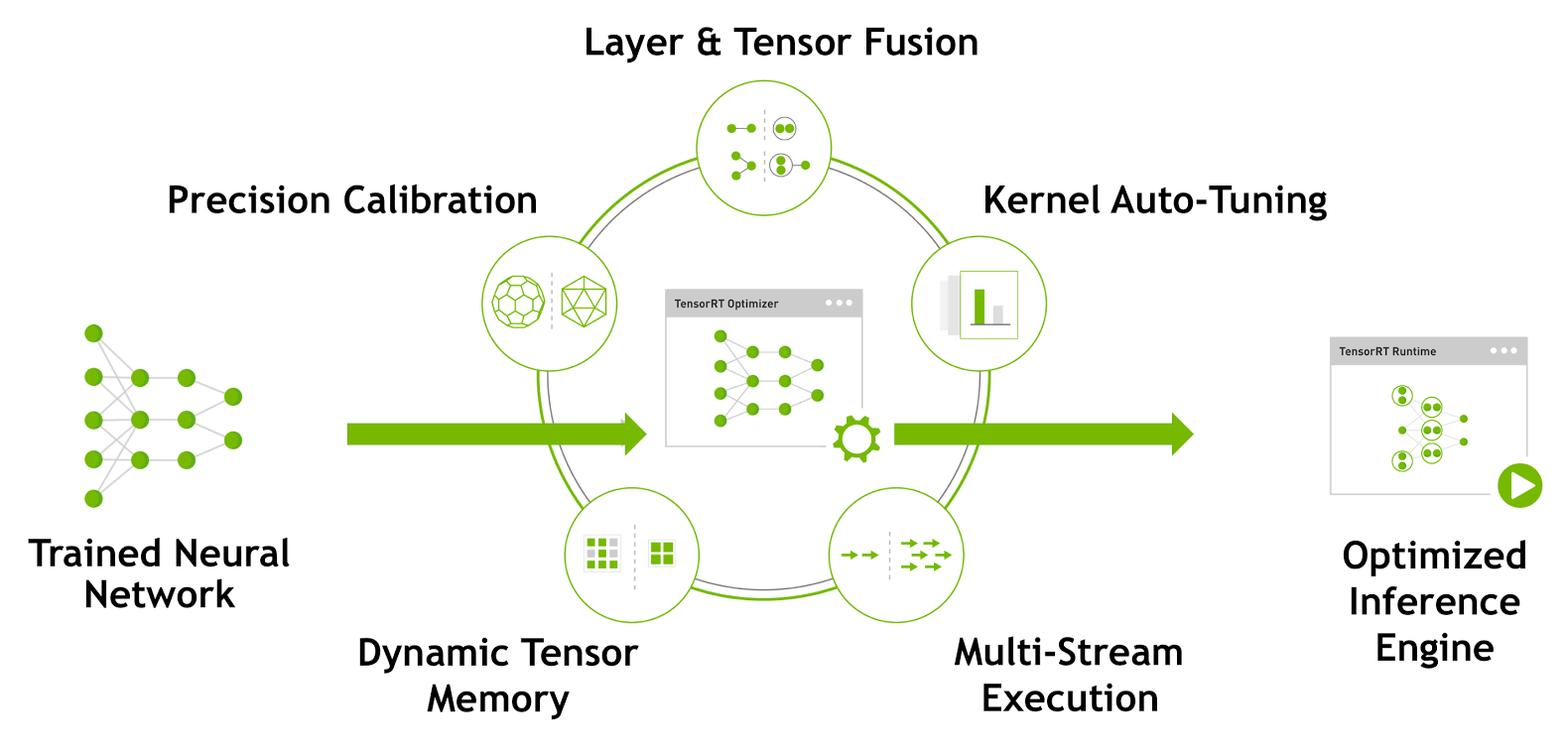
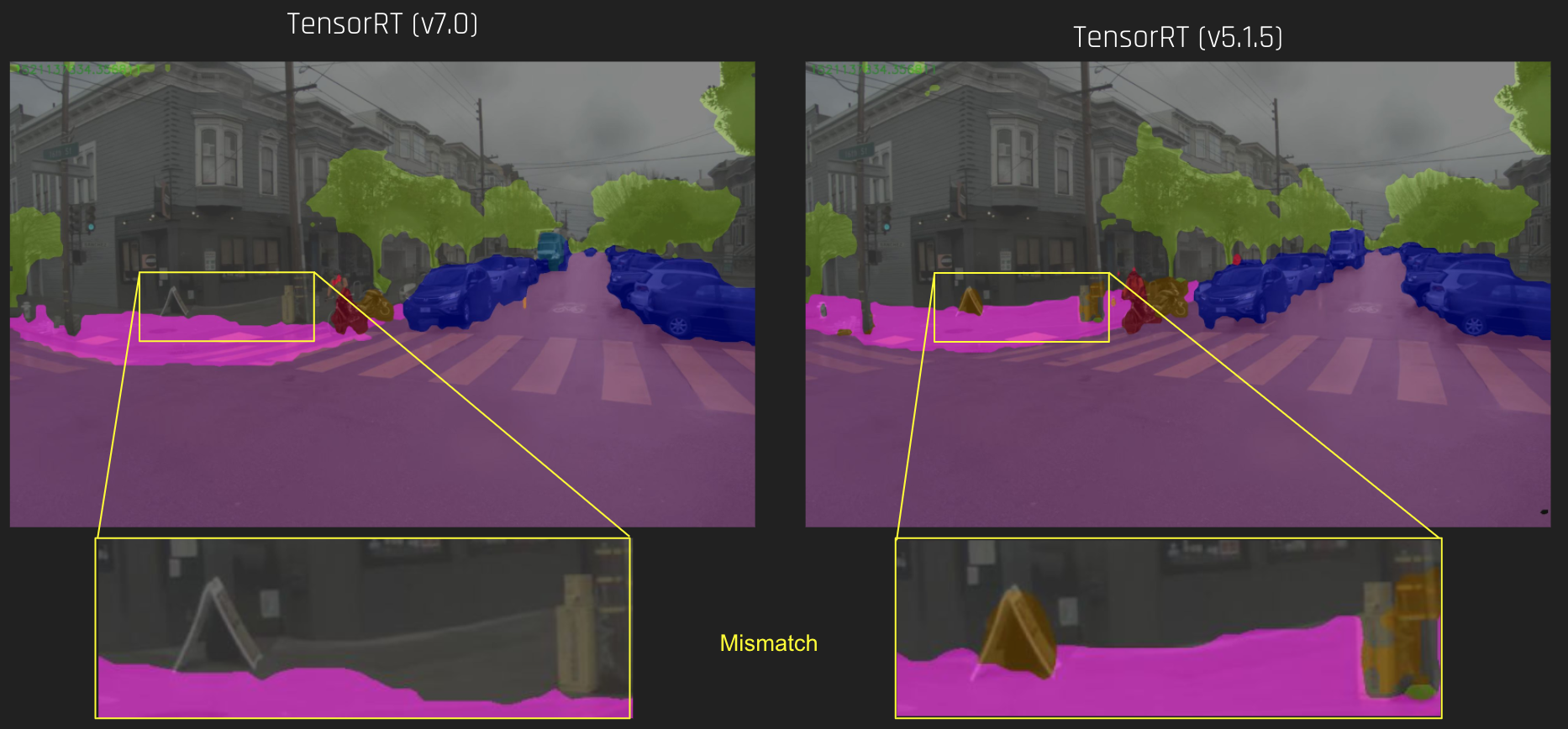
Fast INT8 Inference for Autonomous Vehicles with TensorRT 3 | NVIDIA ...
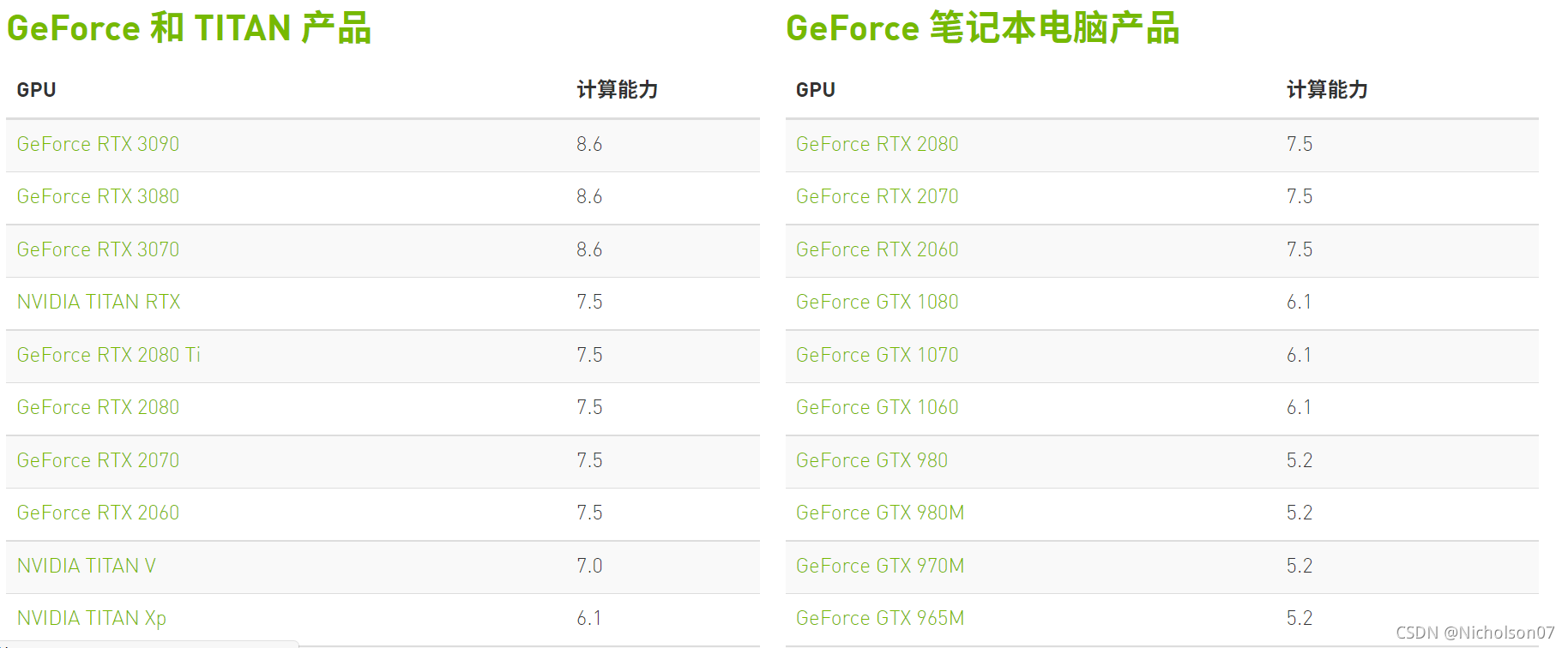
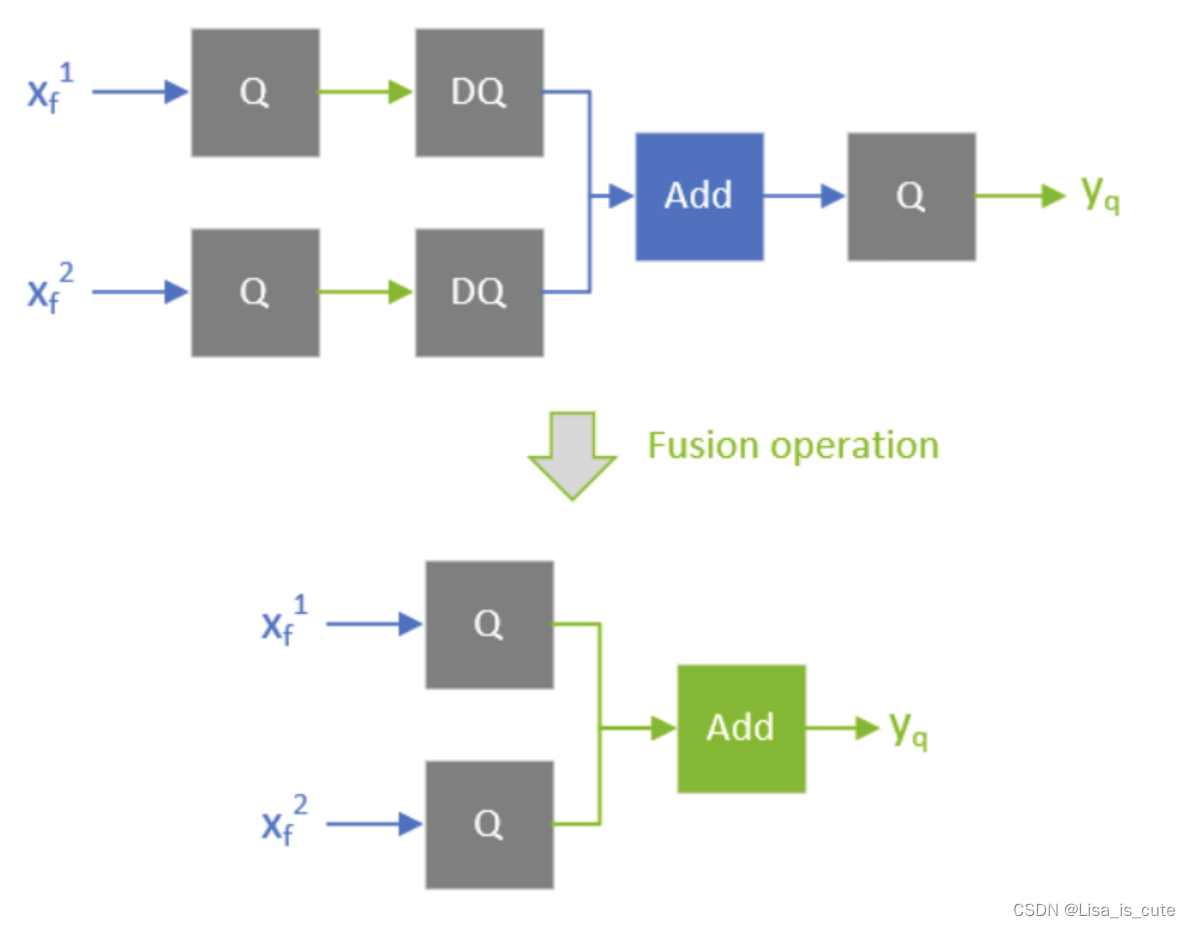
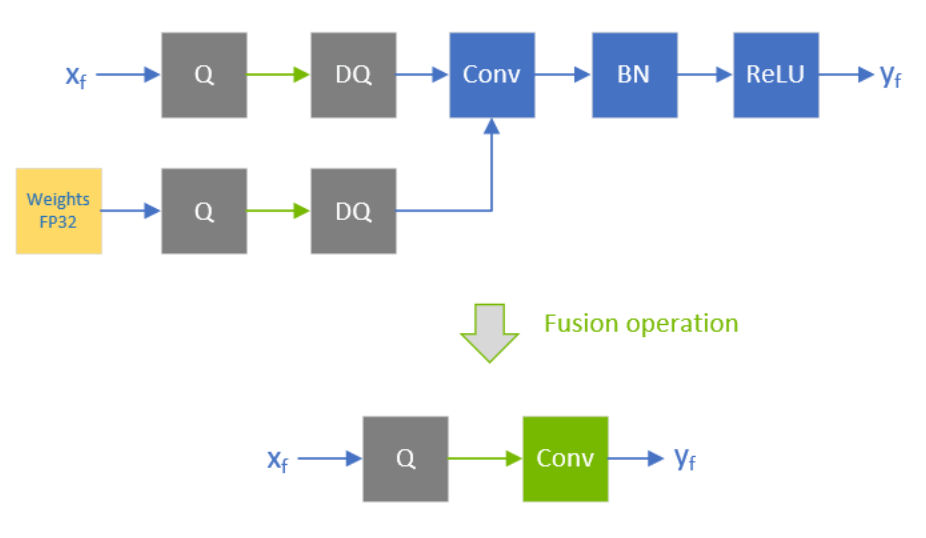
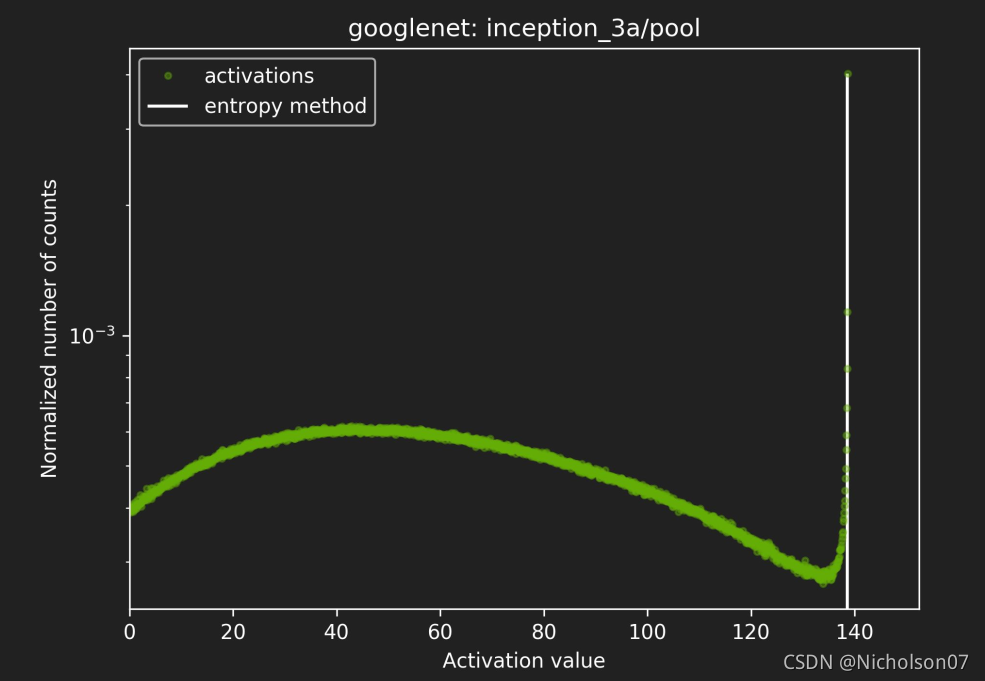
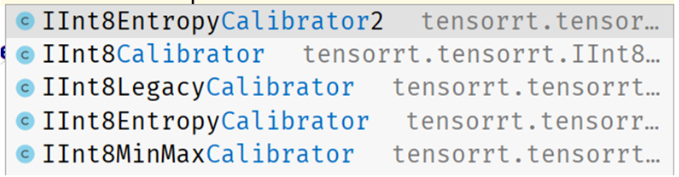
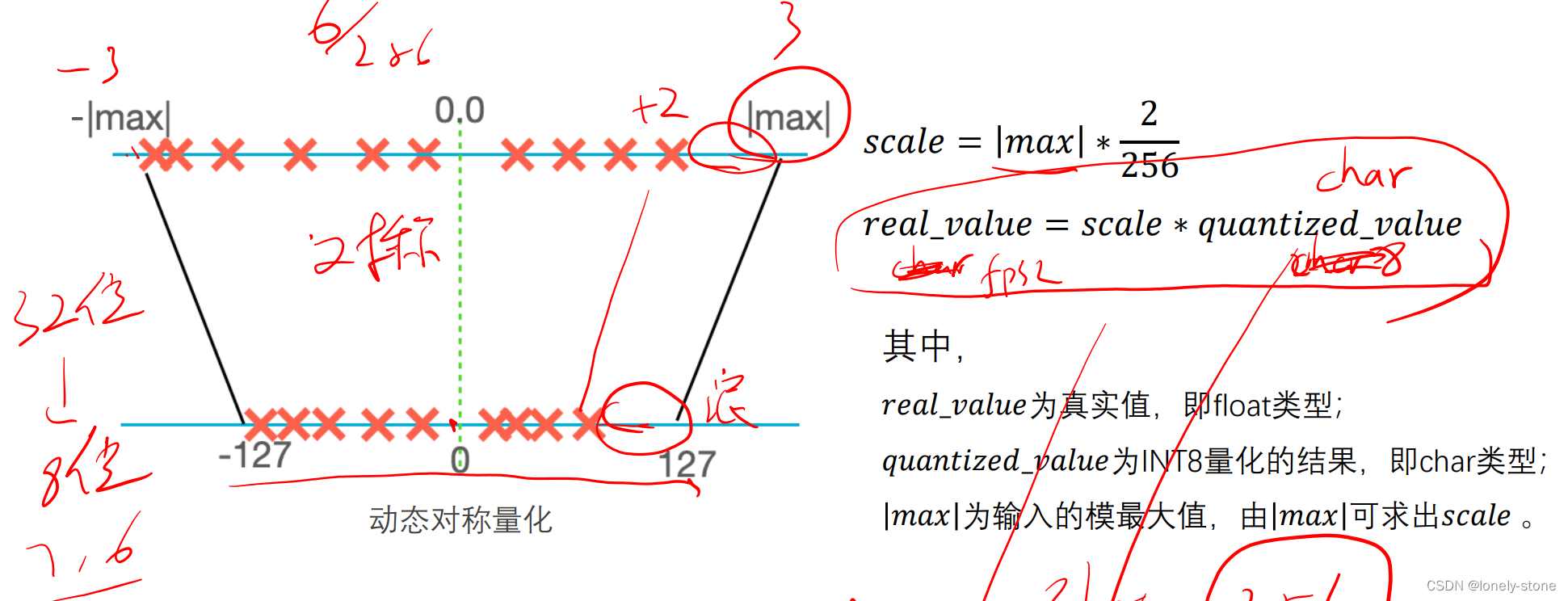
TensorRT INT8量化原理以及如何编写校准器类进行校准_tensorrt int8 生成校准文件-CSDN博客
GitHub - whitelok/tensorrt-int8-python-sample: TensorRT Int8 Python ...
How does TensorRT implements the `Add` in INT8 mode ? · Issue #1144 ...
TensorRT 5 INT8 calibration sample failing · Issue #389 · NVIDIA ...
TensorRT INT8 calibration python API · Issue #2322 · NVIDIA/TensorRT ...
NVIDIA TensorRT INT8 & FP8 quantization accelerating SD inference : r ...
will input be quantified in tensorrt int8 mode · Issue #2927 · NVIDIA ...
TensorRT int8 engine (convert from qat onnx using pytorch-quantization ...
Inconsistent result of INT8 inferencing in TensorRT 8.6 when running ...
TensorRT Deconvolution in INT8 mode gives obviously wrong result ...
When I use the TensorRT to infer MoblieNet in the INT8 mode,I meet the ...
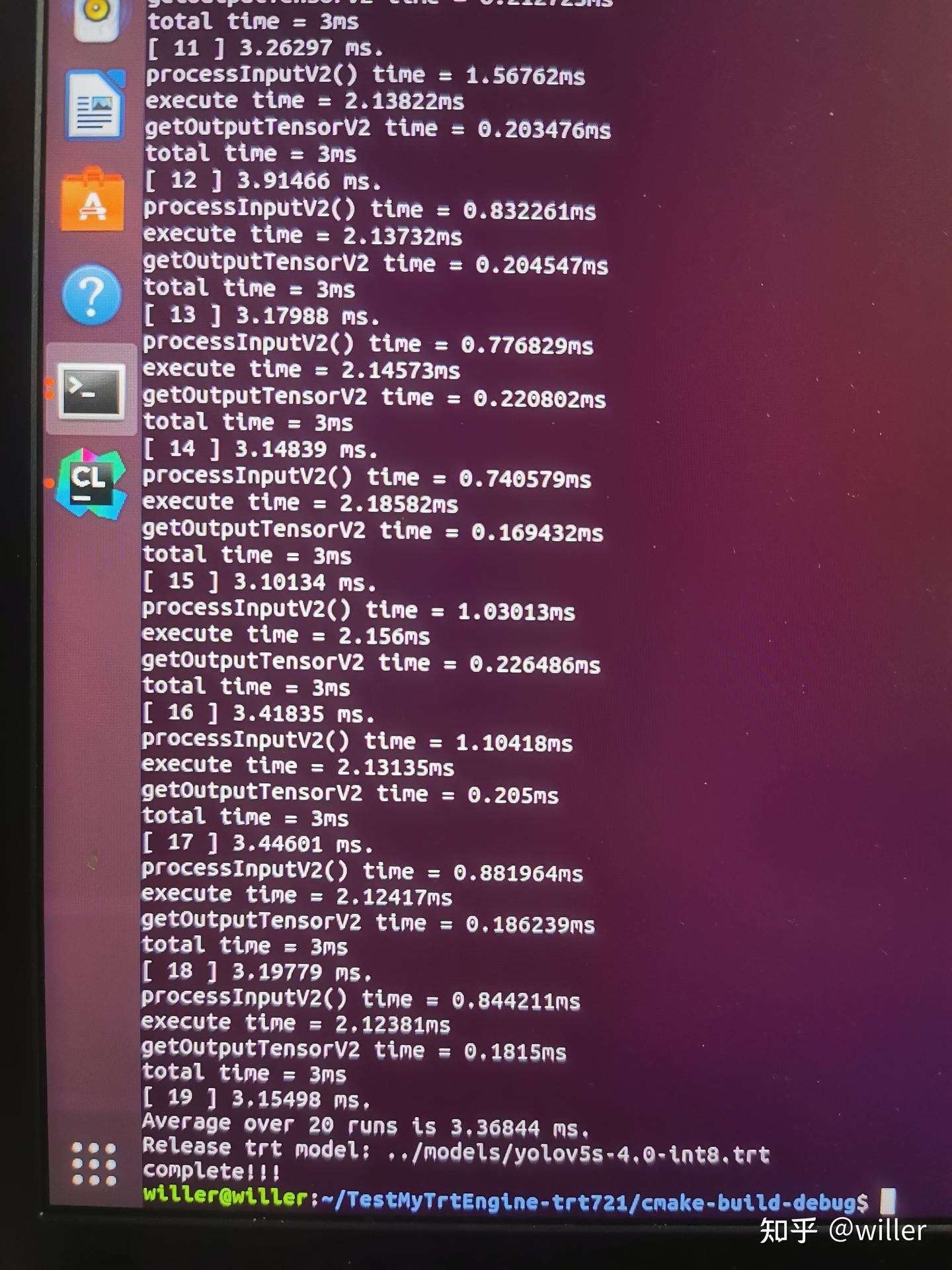
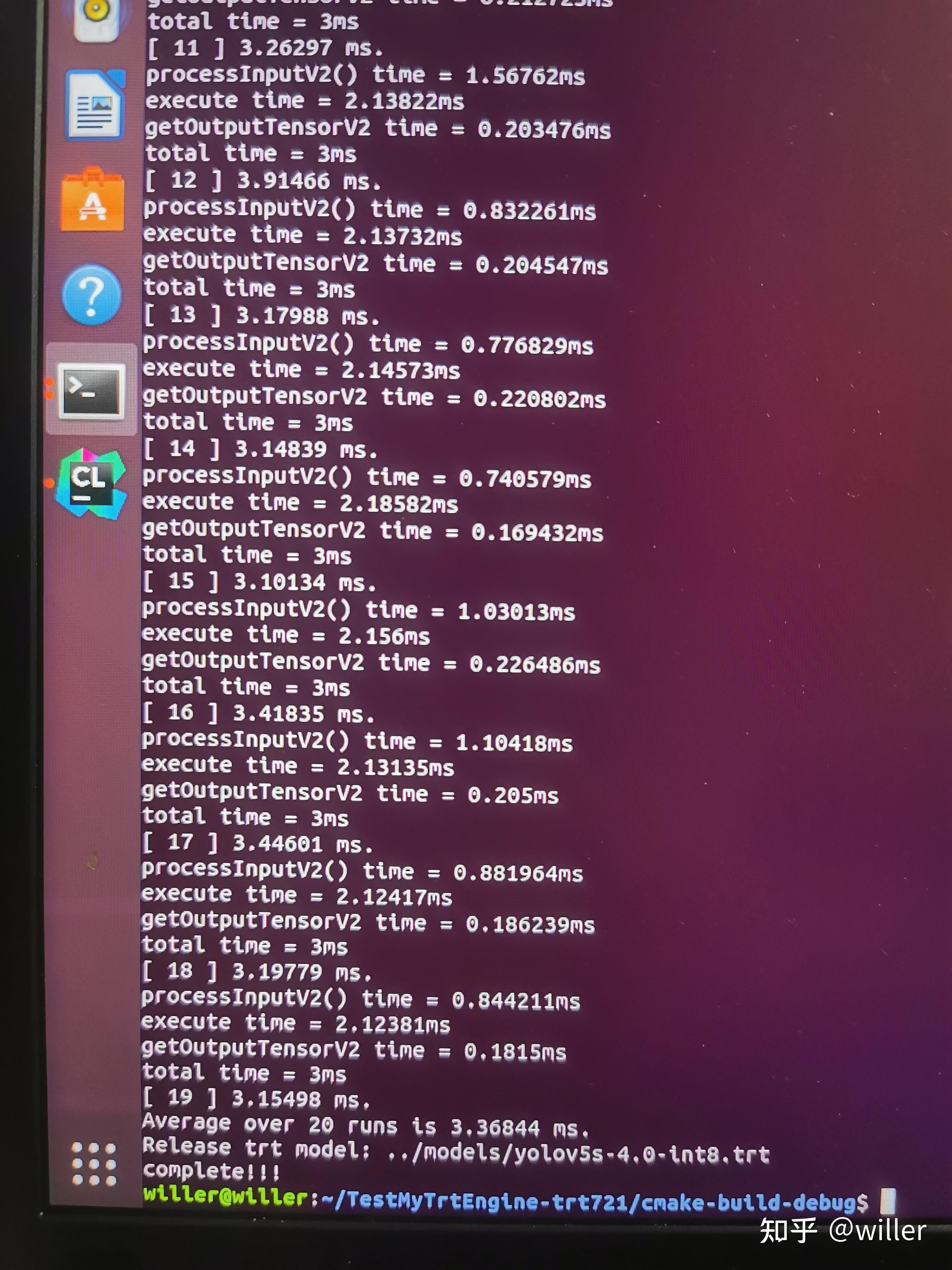
TensorRT int8 量化部署 yolov5s 5.0 模型 - 知乎
INT8 中的稀疏性:NVIDIA TensorRT 加速的训练工作流程和最佳实践 - 知乎
Can I write a plugin that only support INT8 implementation in TensorRT ...
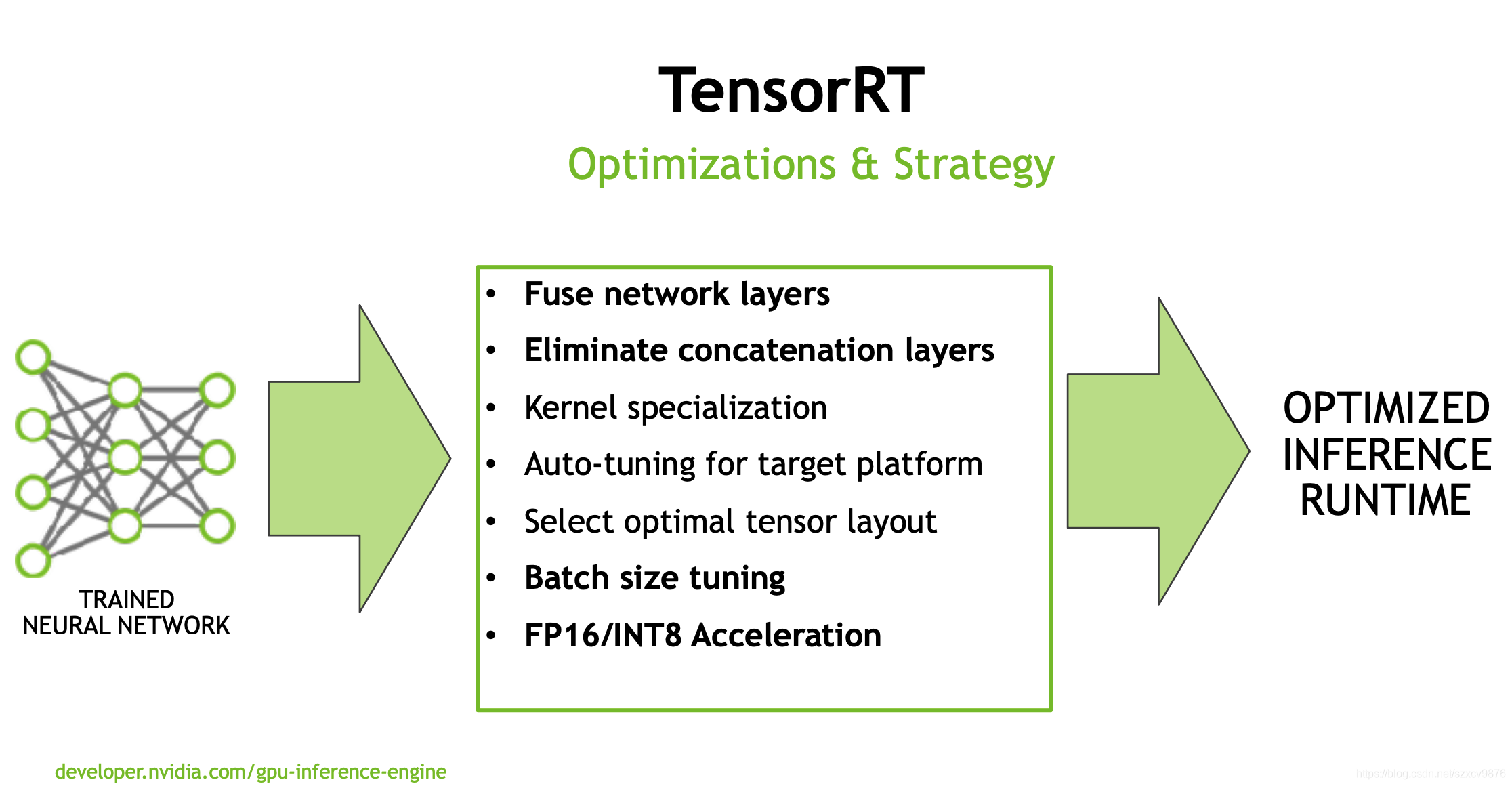
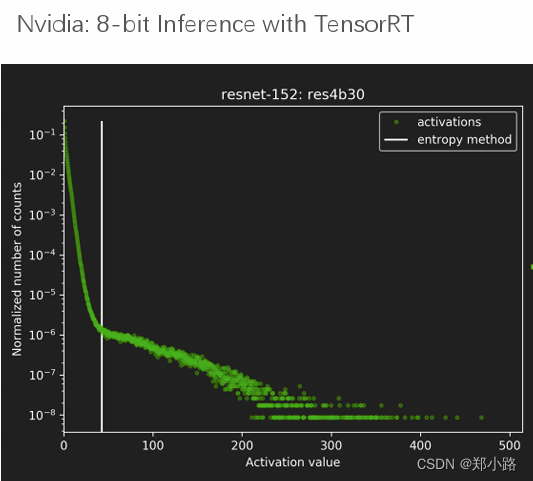
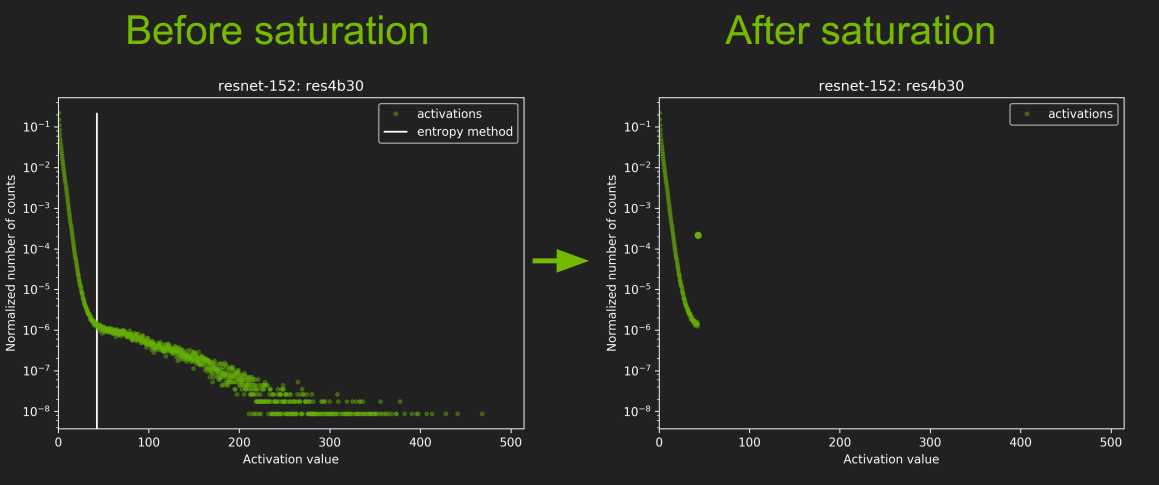
7. TensorRT 中的 INT8 - NVIDIA 技术博客
TensorRT int8 calibration table生成及解析-CSDN博客
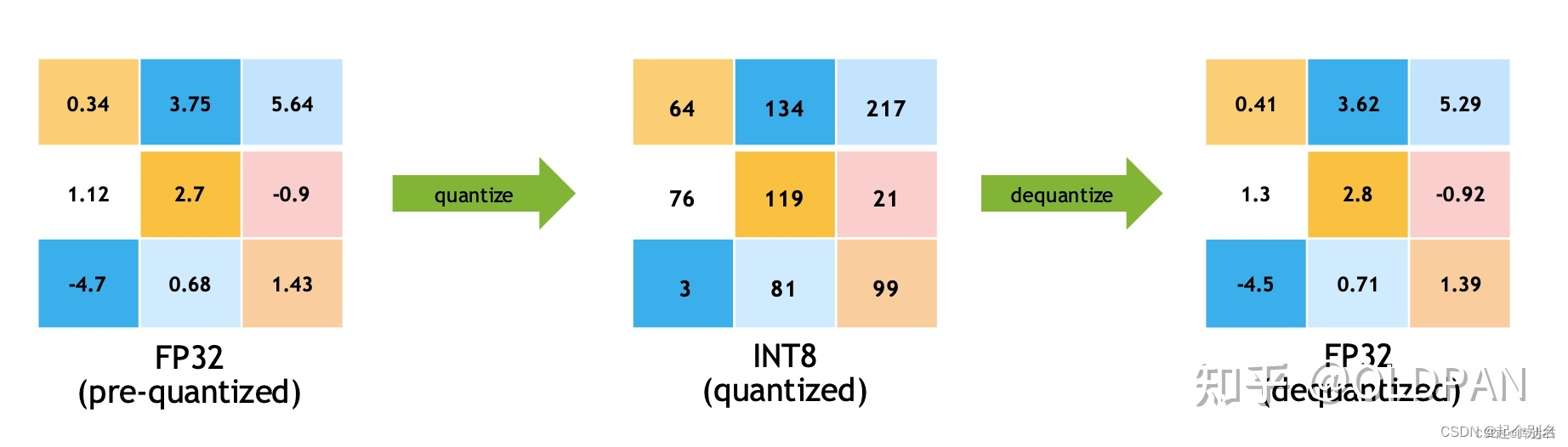
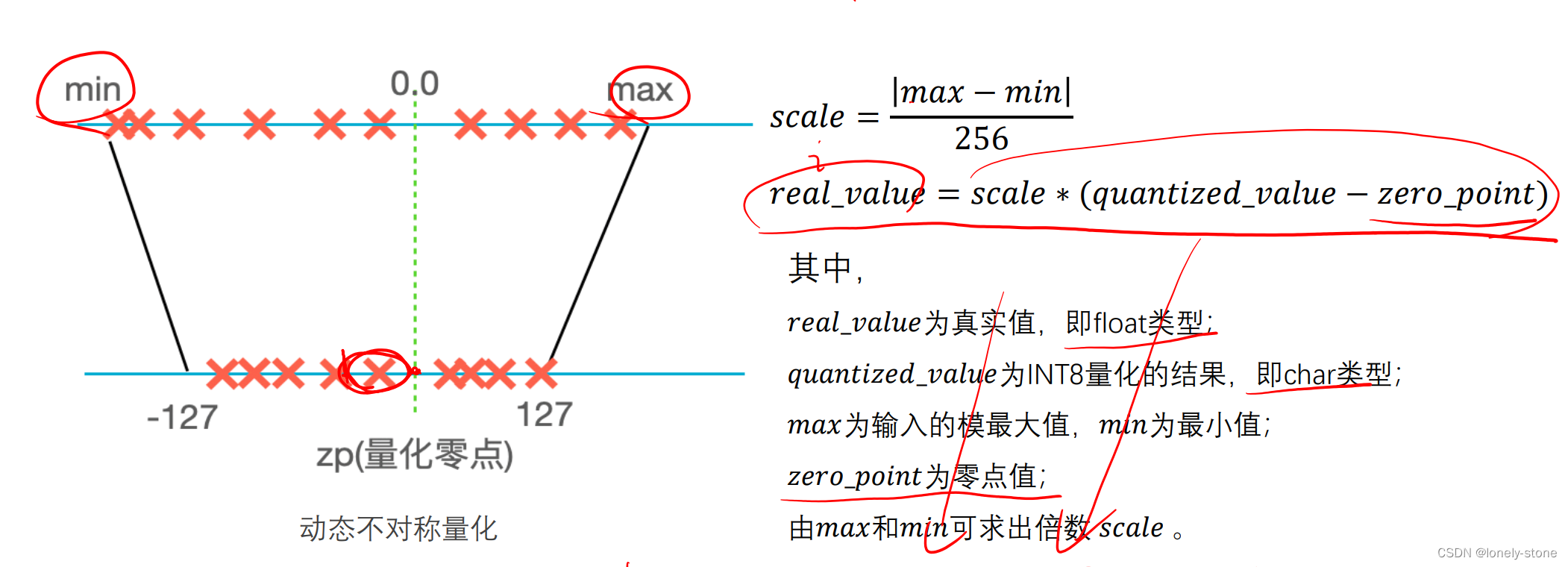
TensorRT INT8 量化原理和实现_tensorrt int8量化-CSDN博客
TensorRT 5 Int8 Calibration Example - TensorRT - NVIDIA Developer Forums
Migrating INT8 calibration from TensorRT 6 to TensorRT 7 in YoloV3 and ...
TensorRT int8 slower than FP16 due to reformat layer - TensorRT ...
TensorRT INT8量化原理与实现(非常详细)-CSDN博客
TensorRT INT8量化实战:在保持精度的同时提速推理-CSDN博客
tensorrt int8量化原理几点问题记录 - 灰太狼锅锅 - 博客园
How to get INT8 calibration cache format in TensorRT? · Issue #625 ...
Question about quantized INT8 model inference · Issue #2404 · NVIDIA ...
Pointers for TensorRT model with uint8/int8 input · Issue #3914 ...
Details about Int8 · Issue #4 · NVIDIA/TensorRT · GitHub
INT8 quantization with same model and different weights · Issue #2705 ...
When inferring in int8 precision, must we call setDynamicRange() for ...
Nvidia TensorRT Document-- int8量化部分_可支持量化的网络层-CSDN博客
The model after INT8 quantization is slower than before and with higher ...
Poor inference results of TensorRT 8.6.3 when running INT8-calibration ...
TensorRT Powered Model for Ultra-Fast Li-Ion Battery Capacity ...
A question about int8 explicit quantization for plugins · Issue #1616 ...
Jetson Orin Nano 15W 模式 Stable Diffusion 20 fps:TensorRT INT8 量化踩坑记 ...
TensorRT模型转换及部署,FP32/FP16/INT8精度区分_tensorrt engine in fp16-CSDN博客
TensorRT:INT8量化加速原理与问题解析_tensorrt int8-CSDN博客
TensorRT-Int8量化详解_tensorrt int8量化-CSDN博客
tensorrt-int8量化介绍_tensorrt int8-CSDN博客
51OpenLab-一站式ICT创新服务平台
TensorRT(5)-INT8校准原理 | arleyzhang
TensorRT——INT8推理 - 渐渐的笔记本 - 博客园
CUDA与TensorRT(7)之TensorRT INT8加速_cuda int8-CSDN博客
GitHub - xuanandsix/Tensorrt-int8-quantization-pipline: a simple ...
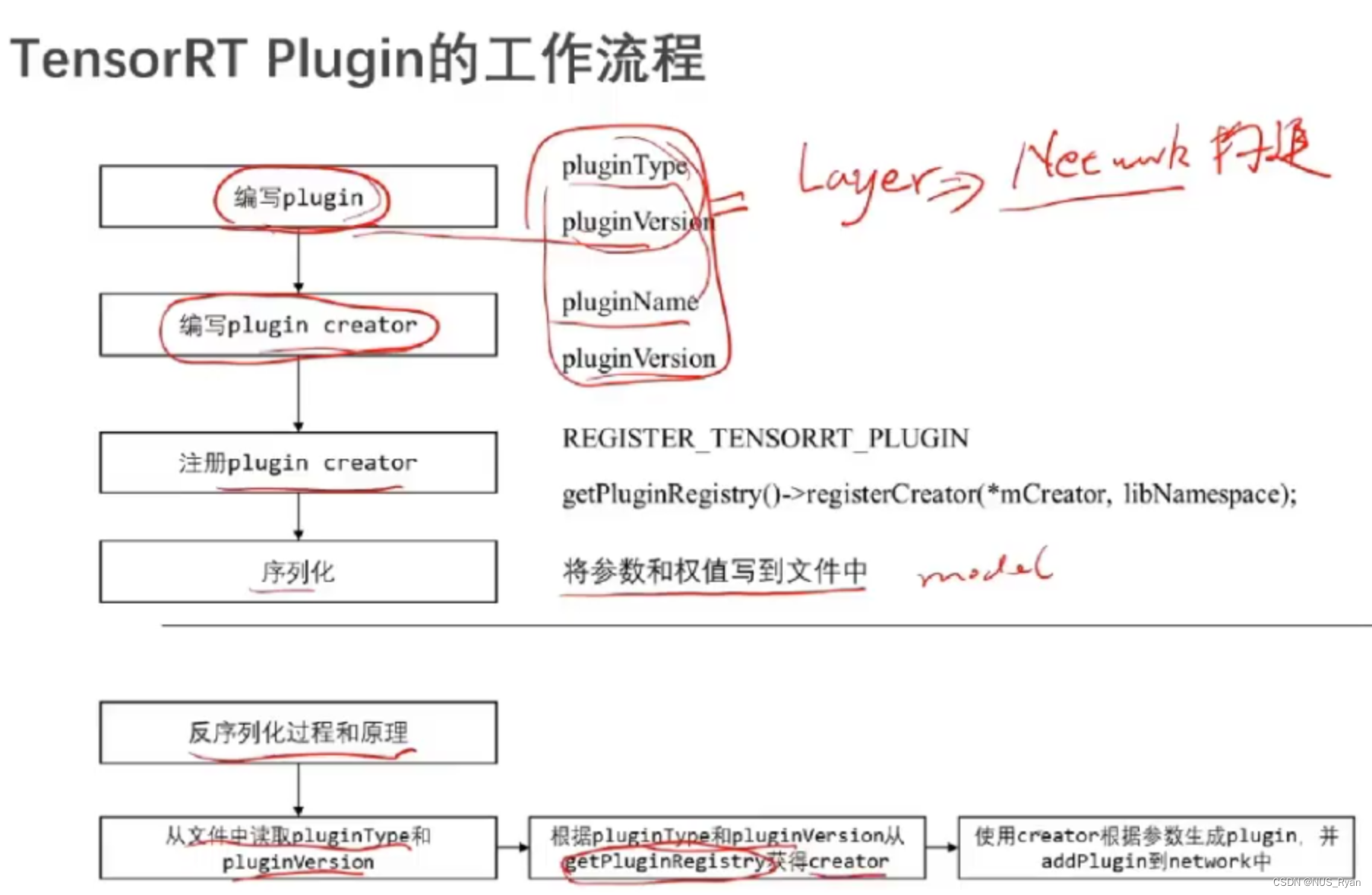
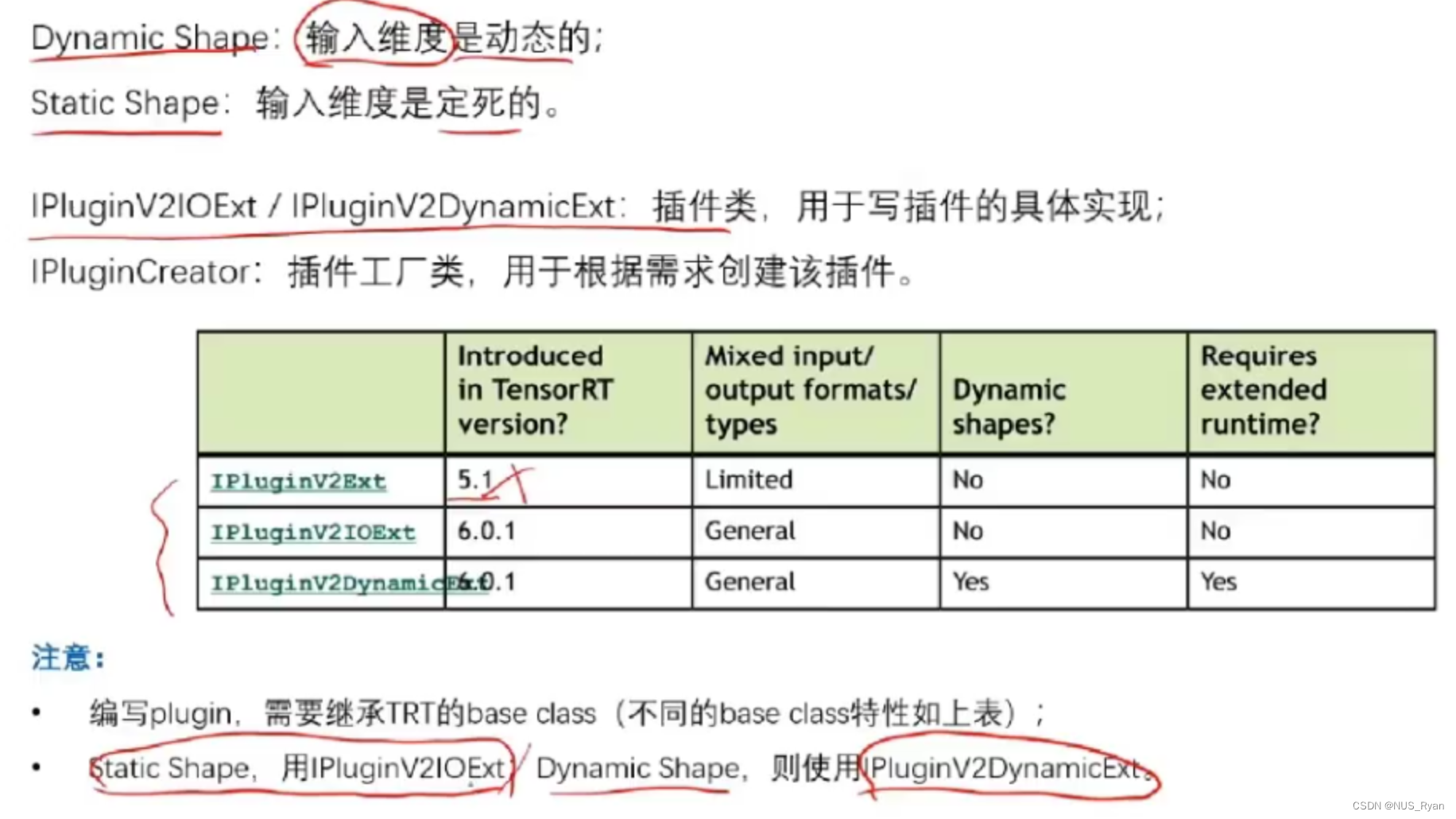
TensorRT入门实战,TensorRT Plugin介绍以及TensorRT INT8加速_tensorrt实战-CSDN博客
tensorrt's native int8(best) is slower than fp16 for FasterVit[TensorRT ...
MobileVit在TensorRT中的int8量化实践与优化挑战-CSDN博客
7.TensorRT中文版开发教程-----TensorRT中的INT8量化详解_tensorrt int8-CSDN博客
TensorRT部署YoloX:int8量化_yolotensorrt int8量化-CSDN博客
5.6.tensorRT基础(2)-学习编译int8模型,对模型进行int8量化_tensorrt隐式量化-CSDN博客
基于tensorRT方案的INT8量化实现原理 – 源码巴士
YOLO11部署优化:极限轻量化 | YOLO11结合PTQ(训练后量化)技术,INT8精度无损转化,TensorRT推理速度翻倍 ...
5 加速DFormerv2(INT8) - 知乎
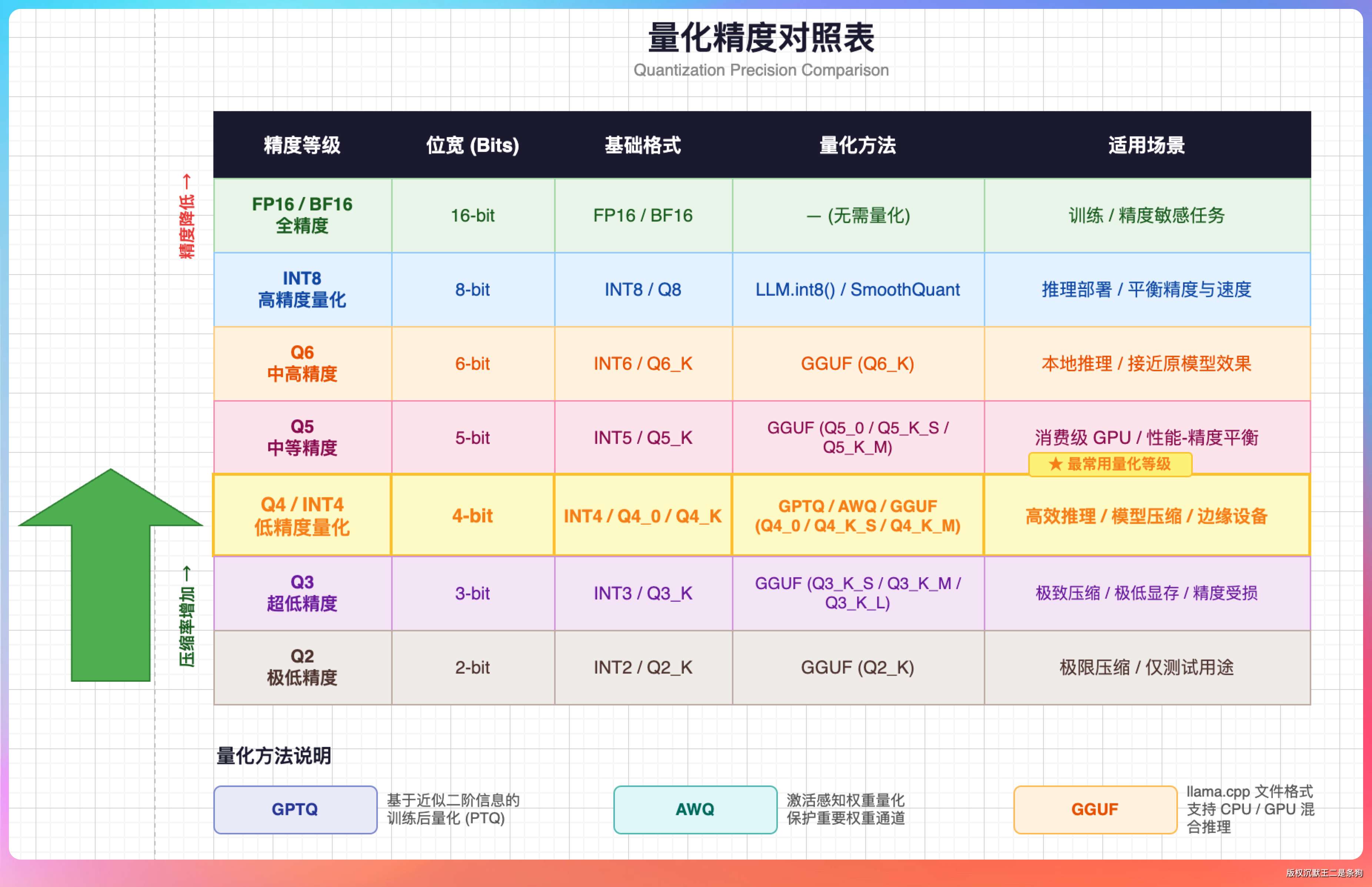
Optimizing LLMs for Performance and Accuracy with Post-Training ...
手机用的大模型开源了,MiniCPM-V 4.6 真的顶。 | 二哥的Java进阶之路
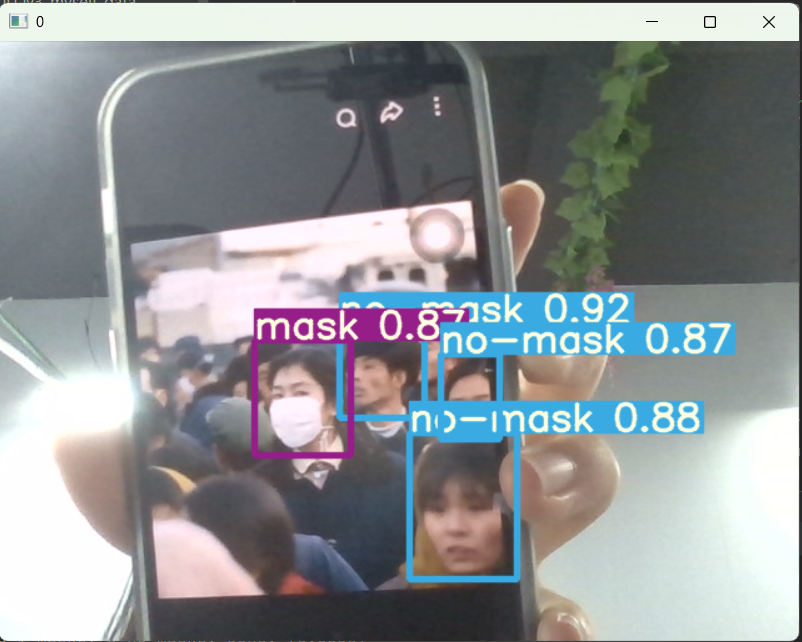
深入浅出 YOLOv5:从核心原理到实战部署全攻略-CSDN博客
New Release: Ultralytics v8.4.61 - Discussion - Ultralytics
Qwen3.7 Preview:阿里通义千问旗舰预览版,智能体与多模态性能双登顶 | AI铺子
Compare Local LLM GPU and NPU Benchmarks | LocalLLMBench
大模型推理加速2026:从500ms到80ms的完整优化路径_主流大模型的推理速度参考-CSDN博客